 by
by Every time you send a photo on WhatsApp, load a website, or play a song on your phone, there’s a mathematical idea from the early 1950s working silently deep inside your device. It was born from a desperate attempt by a student to avoid a university exam, and it ended up becoming one of the structural pillars of the digital age.
It all began in the fall of 1951, in the classrooms of the Massachusetts Institute of Technology (MIT). Professor Robert Fano made his graduate students an unusual offer: they could either face the dreaded final exam in Information Theory, or skip it entirely if they managed to solve an open problem. The challenge was to find the most efficient possible way to encode information in binary.
It was no small task. Fano himself had not managed to find the optimal solution, and neither had the legendary Claude Shannon, the father of information theory. Even so, David Huffman, a twenty‑something student, decided to give it a shot. He wasn’t driven by academic ambition, but by the simple desire to avoid taking that exam.
For weeks he made no progress. On the night before the deadline, frustrated and on the verge of giving up, he threw his notes into the trash. And that’s when he saw it. He had a simple, brutal and mathematically perfect idea. Not only did he pass the course, outdoing his own professors, but he also created an algorithm that, more than seventy years later, is still compressing the world.
The “flat‑rate” problem of bits
To understand the magnitude of Huffman’s breakthrough, it’s enough to look at how we usually store text: we assume that every symbol takes up exactly the same space.
In standard systems like traditional ASCII, each character gets a fixed block of bits (typically 8 bits, or 1 byte), no matter which one it is. The vowel “E”, which appears all the time, costs 8 bits; the consonant “W”, almost anecdotal in Spanish, also pays 8 bits.
Same storage price for symbols with radically different usage: a true flat‑rate for bits that becomes deeply inefficient once you scale up to massive databases or cloud servers. In the end, you consume more space, clog bandwidth, and push costs up.
The CARRERA experiment: paying according to usage
Let’s put some numbers on this waste with a word that feels very appropriate for these hectic times: CARRERA (Spanish for “race”).
It has 7 characters. In a fixed‑length system (ASCII at 8 bits per character), the math is straightforward: 7 characters × 8 bits = 56 bits.
Now let’s apply Huffman’s way of looking at things and do a quick frequency audit:
- C: 1 time
- E: 1 time
- A: 2 times
- R: 3 times
There’s no single letter that completely dominates the message, but the traditional system ignores these differences entirely and charges the same resources to all of them.
How to build the tree step by step
Huffman attacked this problem by building a binary tree with a single, simple rule: always join the two least frequent symbols into the same branch.
In the case of CARRERA (Spanish for “race”), the process works like this:
- We sort the letters by frequency, from the least repeated to the one that appears the most (in this case, R).

- We take the two least frequent ones (C and E) and join them into a branch; their combined frequency becomes 2.
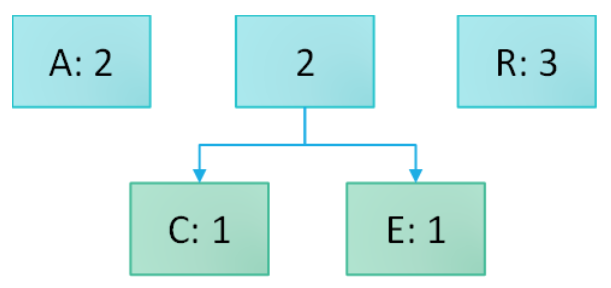
- We repeat the process, always grouping together the elements with the lowest frequency.
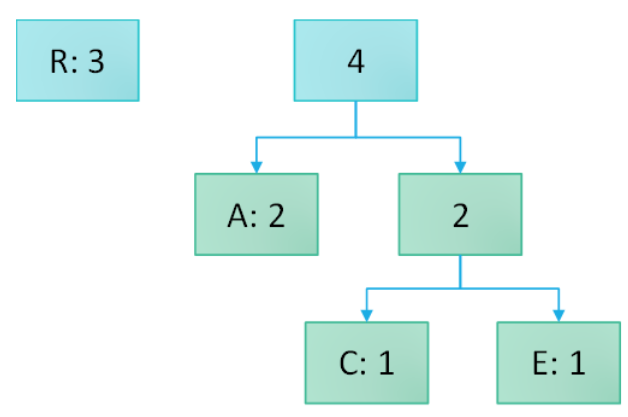
- …until there is only a single root node left that accounts for all 7 occurrences.
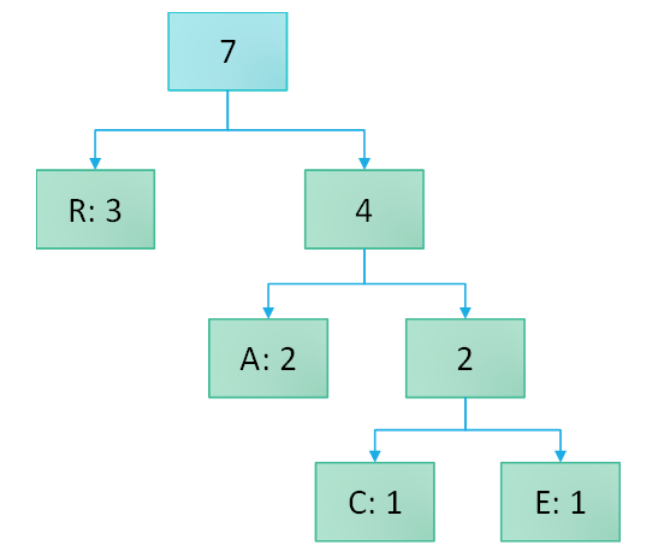
Once we have the tree, we assign 0 when we go down a left branch and 1 when we go down a right branch, until we reach each letter.
The result is a coding system where the most used letters get the shortest codes:
- R: 0 (1 bit)
- A: 10 (2 bits)
- C: 110 (3 bits)
- E: 111 (3 bits)
The cotton test: counting the bits
If we translate CARRERA using these new codes, the numbers leave little room for doubt:
- R: 3 times × 1 bit = 3 bits
- A: 2 times × 2 bits = 4 bits
- C: 1 time × 3 bits = 3 bits
- E: 1 time × 3 bits = 3 bits
Adding them up (3 + 4 + 3 + 3), the total size drops to 13 bits.
We have gone from 56 down to 13 bits, saving 43 bits along the way: a reduction of almost 77% in size for a single word.
The technical brilliance: a code without separators
This is where Huffman’s algorithm shows its elegance in computer architecture.
It is a prefix code: the bit sequence for one letter is never the beginning of the code for another. For example, A’s 10 does not overlap with C’s 110.
This means you can read a long sequence of bits from left to right with no explicit separators and still reconstruct the original message unambiguously, which is critical in telecommunications and compression systems.
An invisible engine in your pocket
The internet does not operate at this scale just because we have more technological brute force, but because, seventy years ago, someone decided there was no point in wasting bits.
The discovery of young David Huffman did not remain a mere academic curiosity of the 1950s. His algorithm is now a foundational piece of modern data compression: it is used in file formats like ZIP, in JPEG image compression, and in the audio encoding of many codecs, as well as in multiple video and voice standards.
Every photo you upload, every document you attach, and a large share of the telemetry travelling across the network pass, in one way or another, through an idea that was born to avoid a final exam.
It is tempting to think that the internet runs this smoothly only thanks to 5G networks, giant data centers, or faster solid‑state drives. However, beneath that hardware surface lies a layer of mathematical efficiency that keeps the network from collapsing under its own weight: Huffman did not build faster cables or more powerful processors; he simply made it so that we need to send less data.
The internet does not operate at this scale just because we have more technological brute force, but because, seventy years ago, someone decided there was no point in wasting bits.